Downloaded the announcement of a listed company from cninfo.com.cn and saved it as a PDF file.
The relevant title about it is 国泰君安 - 关于独立董事公开征集投票权的公告.

Let’s extract text and table on the PDF file by python. We have to make sure the library pdfplumber had been installed. Use the command pip install pdfplumber to prepare the environment if there is no pdfplumber.
Extract Text
#! /usr/local/bin/python3
# -*- coding: utf-8 -*-
import pdfplumber
if __name__ == '__main__':
pdf = pdfplumber.open( '/Users/weiyang/Desktop/国泰君安.PDF' )
pages = pdf.pages
target_page = pages[5]
content = target_page.extract_text()
print( content )
pdf.close()

Extract Table
The table in PDF:
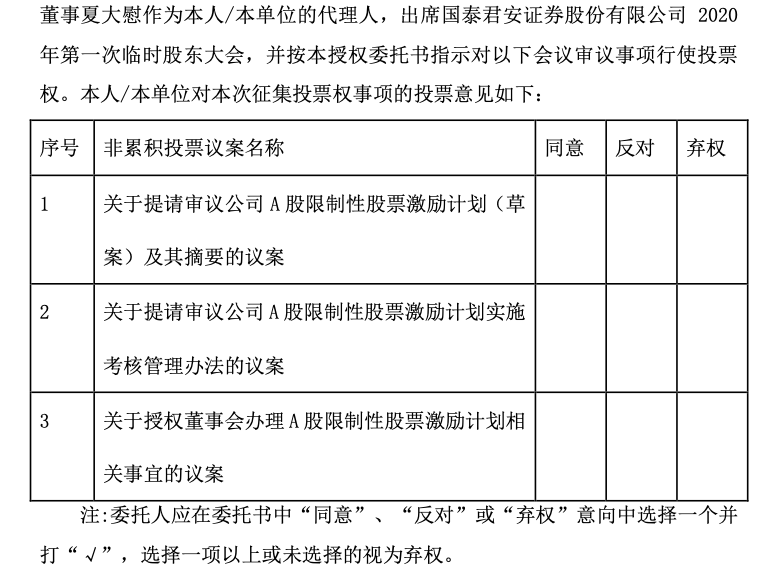
The test script:
#! /usr/local/bin/python3
# -*- coding: utf-8 -*-
import pdfplumber
if __name__ == '__main__':
pdf = pdfplumber.open( '/Users/weiyang/Desktop/国泰君安.PDF' )
pages = pdf.pages
target_page = pages[5]
tables = target_page.extract_tables()
print( tables[0] )
pdf.close()
Output:
[['序号', '非累积投票议案名称', '同意', '反对', '弃权'], ['1', '关于提请审议公司 A股限制性股票激励计划(草\n案)及其摘要的议案', '', '', ''], ['2', '关于提请审议公司A股限制性股票激励计划实施\n考核管理办法的议案', '', '', ''], ['3', '关于授权董事会办理A股限制性股票激励计划相\n关事宜的议案', '', '', '']]
The list format is not friendly to humans. So we have to use the library pandas to handle it and show the data by the local xlsx file.
table = tables[0]
#remove `\n`
for i in range( len(table) ):
for j in range( len(table[i]) ):
table[i][j] = table[i][j].replace('\n', '')
df = pd.DataFrame( table[1:], columns=table[0] )
# show all column
pd.set_option('display.max_columns', None)
df.to_excel( 'data.xlsx', index=False )
Output:

{kind=link}