To find a high-quality book on amazon kindle store, I collect some books information and analyze them. The process can be divided into two main parts.
Part 1. Download books’ information and save them to the database.
We use BeautifulSoup to collect all books’ divs on the web page, convert the div object to string and search book’s title, price, URL of the introduction web page, comment score by regular expressions.
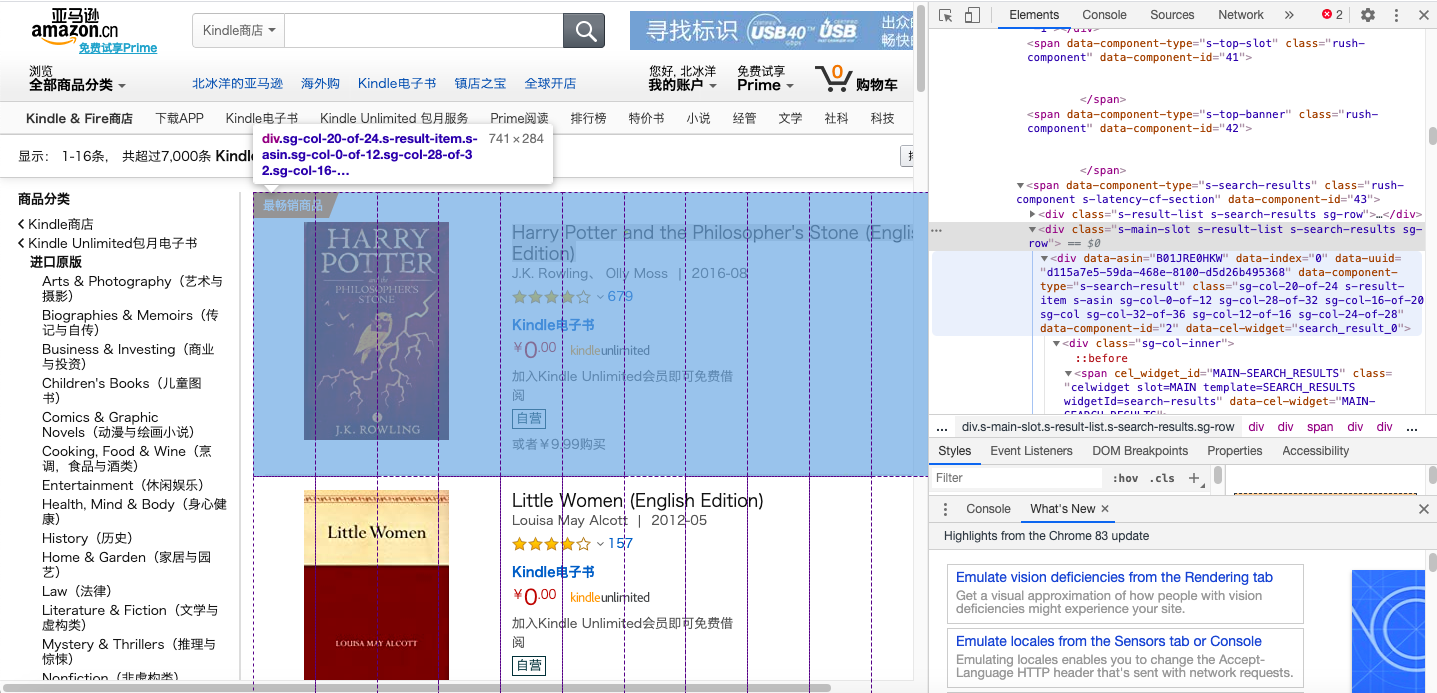
It’s beneficial to set time limitation to avoid long time dormancy. We also need to add request headers for interface requests.get to fetch page’s HTML to fix issue about website’s reject to the automatic robot.
Do you care about the text-encode format? If the answer is yes, it’s better to decode the data to utf-8 or gbk.
It’s worth noting that a few books have not score, even price information, and the number on the web page has string format **,***,***, so we have to handle these special situations.
I planed to record the books’ classified information on the book detail page, but it failed most time due to the web site’s listening and rejection.
Finally, the program writes every book’s information into the database with the help of pymysql library.
#! /usr/local/bin/python3
# -*- coding: utf-8 -*-
import requests
import re
import pymysql
from bs4 import BeautifulSoup
def GetText( URL ):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
res = requests.get( URL, headers=headers, timeout = 10 ).text
code = requests.get( URL, headers=headers, timeout = 10 ).encoding
try:
res = res.encode( code ).decode( 'utf-8' )
except:
try:
res = res.encode( code ).decode( 'gbk' )
except:
res = res
return res
def Amazon( URL ):
host = URL.split( '/s?' )[0]
res = GetText( URL )
bs = BeautifulSoup( res, 'html.parser' )
divs = bs.find_all( 'div', { 'data-asin': re.compile('[A-Z0-9]{10}') } )
for div in divs:
text = str( div )
titles = re.findall( '<span class="a-size-medium a-color-base a-text-normal" dir="auto">(.*?)</span>', text )
hrefs = re.findall( '<a class="a-link-normal a-text-normal" href="(.*?)" target="_blank">', text )
hrefs[0] = host + hrefs[0]
prices = re.findall( '<span dir="auto">或者(.*?)购买</span>', text )
vars = re.findall( '<span aria-label="(.*?)"', text )
db = pymysql.connect( host='localhost', port=3306, user='root', password='wy19941212', database='PySpider' )
cur = db.cursor()
score = ''
numberOfMen = ''
if len( vars ) >= 2:
score = vars[0]
score = score.split( '颗星,' )[0]
numberOfMen = vars[1]
if numberOfMen.find( ',' ) >= 0:
numberOfMen = numberOfMen.replace( ',', '' )
# Fetch reading tag
bookDetails = GetText( hrefs[0] )
bookBs = BeautifulSoup( bookDetails, 'html.parser' )
bookTags = bookBs.find_all( 'li', { 'class' : 'zg_hrsr_item' } )
if len(bookTags) == 0:
print( "Can't fetch bookDetails due to amazon " )
tagsString = ''
for bookTag in bookTags:
bookTagText = str( bookTag )
tagRank = re.findall( '<span class="zg_hrsr_rank">(.*?)</span>', bookTagText )
tagName = re.findall( '<span class="zg_hrsr_ladder">.*?>(.*?)</a></span>', bookTagText )
if( len( tagName ) > 0 ):
tagsString = tagsString + tagRank[0] + ' - ' + tagName[0] + '\n'
if numberOfMen == '':
numberOfMen = '0'
if score == '':
score = '0'
priceValue = ''
if len( prices ) == 0:
prices = re.findall( '<span class="a-price" data-a-size="l" data-a-color="price"><span class="a-offscreen">(.*?)</span>', text )
if len( prices ) > 0:
priceValue = prices[0]
priceValue = re.sub( '¥', '', priceValue )
if priceValue == '':
priceValue = '0'
try:
# sql = 'INSERT INTO Books(title, price, score, menCount, url, tags) ' \
# 'VALUES (%s, %f, %f, %d, %s, %s)'
# cur.execute( sql, ( titles[0], float(priceValue), float(score), int(numberOfMen), hrefs[0], tagsString ) )
sql = 'INSERT INTO Books(title, price, score, menCount, url, tags) ' \
'VALUES ("' + titles[0] + '", ' + priceValue + ', ' + score + ', ' + numberOfMen + ', "' \
+ hrefs[0] + '", "' + tagsString + '")'
cur.execute(sql)
print( 'success: ' + hrefs[0] )
except:
print( "failed to insert: " + URL )
print( sql )
db.commit()
cur.close()
db.close()
if __name__ == '__main__':
URLs = []
URLs.append( 'https://www.amazon.cn/s?rh=n%3A1337631071&brr=1&rd=1&ref=sa_menu_kindle_l3_b144154071' ) #first page
pageUrl = 'https://www.amazon.cn/s?i=digital-text&rh=n%3A1337631071&page=2&brr=1&qid=1592640104&rd=1&ref=sr_pg_2/'
URLs.append( pageUrl )
for i in range(298):
i = i+3
tmp = 'page=' + str(i) + '&brr'
newUrl = pageUrl.replace( 'page=2&brr', tmp )
tmp = 'sr_pg_' + str(i) + '/'
newUrl = newUrl.replace( 'sr_pg_2/', tmp )
URLs.append( newUrl )
for URL in URLs:
Amazon( URL )
Part 2. Analyze data
I read all data in the MySQL table, ignore all books that the number of comment persons is less than 100 and sort them by the result of the book’s score value divided by the number of persons, after that our program writes the data into excel file.
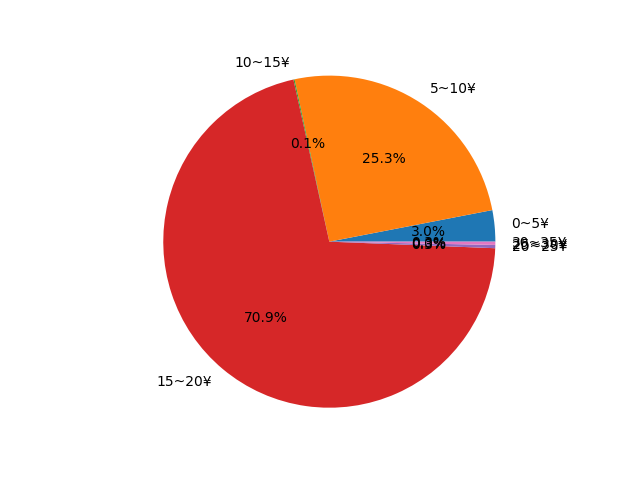
In the final stage, I count the number of books in each price range and show the statistics result in the pie image.
#! /usr/local/bin/python3
# -*- coding: utf-8 -*-
import pymysql
import matplotlib.pyplot as plt
import pandas as pd
if __name__ == '__main__':
db = pymysql.connect( host='localhost', port=3306, user='root', password='wy19941212', database='PySpider' )
cur = db.cursor()
sql = 'SELECT * FROM Books WHERE menCount >= 100'
cur.execute( sql )
books = cur.fetchall()
books = sorted( books, key = lambda book: book[2]/book[3], reverse=True )
columns = [ 'title', 'price', 'score', 'menCount', 'url', 'tags' ]
df = pd.DataFrame( books, columns=columns )
writer = pd.ExcelWriter(r'/Users/weiyang/Desktop/data.xlsx', engine='openpyxl')
df.to_excel( writer, sheet_name='Books' )
writer.save()
writer.close()
countForPrice = [0, 0, 0, 0, 0, 0, 0]
labels = [ '0~5¥', '5~10¥', '10~15¥', '15~20¥', '20~25¥', '25~30¥', '30~35¥' ]
for book in books:
if book[1] < 5 and book[1] >= 0:
countForPrice[0] = countForPrice[0] + 1
elif book[1] < 10 and book[1] >= 5:
countForPrice[1] = countForPrice[1] + 1
elif book[1] < 15 and book[1] >= 10:
countForPrice[2] = countForPrice[2] + 1
elif book[1] < 20 and book[1] >= 15:
countForPrice[3] = countForPrice[3] + 1
elif book[1] < 25 and book[1] >= 20:
countForPrice[4] = countForPrice[4] + 1
elif book[1] <= 30 and book[1] >= 25:
countForPrice[5] = countForPrice[5] + 1
else:
countForPrice[6] = countForPrice[6] + 1
plt.pie( countForPrice, labels = labels, autopct='%1.1f%%' )
plt.axis('equal')
plt.show()
cur.close()
db.close()
{kind=link}
[…] The books’ sales information is collected from amazon as described in the article Find The Book Wanted In Amazon By Python, you can read it if you are interested about the entire […]